【CUC】计算思维概论-大作业
中国传媒大学的计算思维概论是新闻学专业的同学们需要学习的一门课程,我在协助女朋友完成作业的过程中锻炼到了python的多方面知识,认为这份作业还是有一定的参考价值的,故在此作分享。这份大作业应用了包括网络爬虫、数据分析、tkinter等多方面知识,适合初学者练习使用。但由于本人python编程能力有限,因此对代码无法分析的十分透彻,代码中也许会存在部分错误,请谅解!让我们开始吧!
第一部分:项目简介
本项目选择bilibili热门榜作为爬取对象,爬取热门榜前100名的视频名称、bv号、播放量等数据。通过分析数据的平均值、数据与排名的走势来预估视频登上排名榜的先决条件。
第二部分:代码实现
需要调用的库
1 | import requests #用于爬取网页 |
爬虫部分
代码实现
1 | url = 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all' |
设计思路&存在的问题
- 不知道随机选取user_agents是否真的能反爬(估计大概率多余)
- 找到数据在table内对应位置的思路:观察上述代码内url链接内的规律

上图为url链接内的数据,通过与代码进行比对,我们就可以很简单地看出来是如何收集的数据。
注: 如需打开url链接,建议使用chrome浏览器数据分析部分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36#此部分代码笔者了解不多,但是大家可以轻易仿照代码写出自己需要的代码,故不另作阐述
data = []
max_value, min_value, average_value = 0, 10e9, 0
for k in range(0,len(table['data']['list'])):
title = table['data']['list'][k]['title']
name = table['data']['list'][k]['owner']['name']
play_num = table['data']['list'][k]['stat']['view']
bv = table['data']['list'][k]['bvid']
danmaku = table['data']['list'][k]['stat']['danmaku']
reply = table['data']['list'][k]['stat']['reply']
like = table['data']['list'][k]['stat']['like']
favorite = table['data']['list'][k]['stat']['favorite']
coin = table['data']['list'][k]['stat']['coin']
share = table['data']['list'][k]['stat']['share']
data.append([k + 1, title, name, play_num, bv, like, reply, danmaku, favorite, coin, share])
if play_num > max_value:
max_value = play_num
if play_num < min_value:
min_value = play_num
average_value += play_num
average_value /= 100
print('最大播放量:' + str(max_value) + ' 最小播放量:' + str(min_value) + '平均播放量:' + str(int(average_value)))
df = pd.DataFrame(data, columns=['排名', '标题', '作者', '播放量', 'BV号', '点赞数', '回复数', '弹幕数', '收藏数', '投币数', '分享数'])
df.to_excel('bilibili_rank.xlsx', index=False) # 放到excel里
x = np.linspace(0, 100, 100)
y = df["播放量"].values
l, = plt.plot(x, y, color='red')
plt.xlim((0, 100))
plt.ylim((0, 7000000))
plt.xlabel("rank", {"size" : 23})
plt.ylabel("view", {"size" : 23})
plt.title("rank&play_num",fontsize=25)
plt.grid()
plt.legend(handles=[l], labels=["rank&play_num"], loc='best')
plt.savefig("rank&play_num.jpg")
plt.show()UI部分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17#此部分代码笔者了解不多,但是大家可以轻易仿照代码写出自己需要的代码,故不另作阐述
window = Tk()
window.title("网页数据收集...")
window.geometry('800x600+10+10')
window.configure(bg='HotPink')
Label(window, text='', bg='HotPink').grid(row=1, column=10)
Label(window, text=' ~~ 视频排行榜数据获取 ~~', font = ("Arial", 40), bg='HotPink').grid(row=2, column=4)
Label(window, text='', bg='HotPink').grid(row=3, column=10)
def start():
Label(window, text='开始...', font = ("Arial", 20), bg='HotPink').grid(row=10, column=4)
Label(window, text='最大播放量:' + str(max_value) + ' 最小播放量:' + str(min_value) + '平均播放量:' + str(int(average_value)), font = ("Arial", 20), bg='HotPink').grid(row=12, column=4)
Label(window, text='完成!', font = ("Arial", 20), bg='HotPink').grid(row=13, column=4)
Button(window, text='开始数据收集', font = ("Arial", 30), width=12, command=start) \
.grid(row=4, column=4, sticky=E, padx=10, pady=5)
Button(window, text='退出', font = ("Arial", 30), width=5, command=window.quit) \
.grid(row=5, column=4, sticky=E, padx=10, pady=5)
window.mainloop()第三部分:效果展示

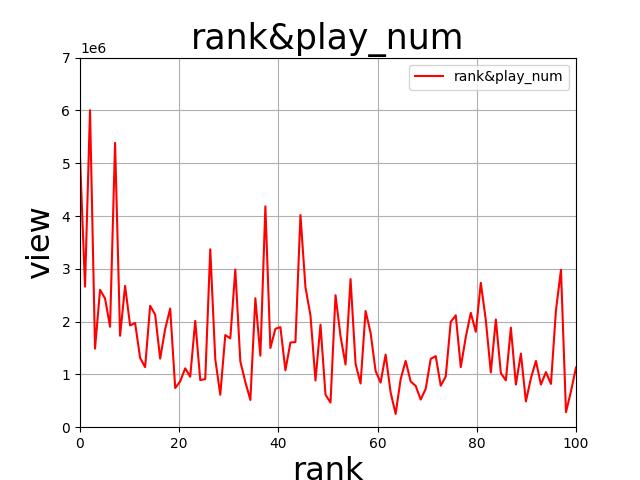
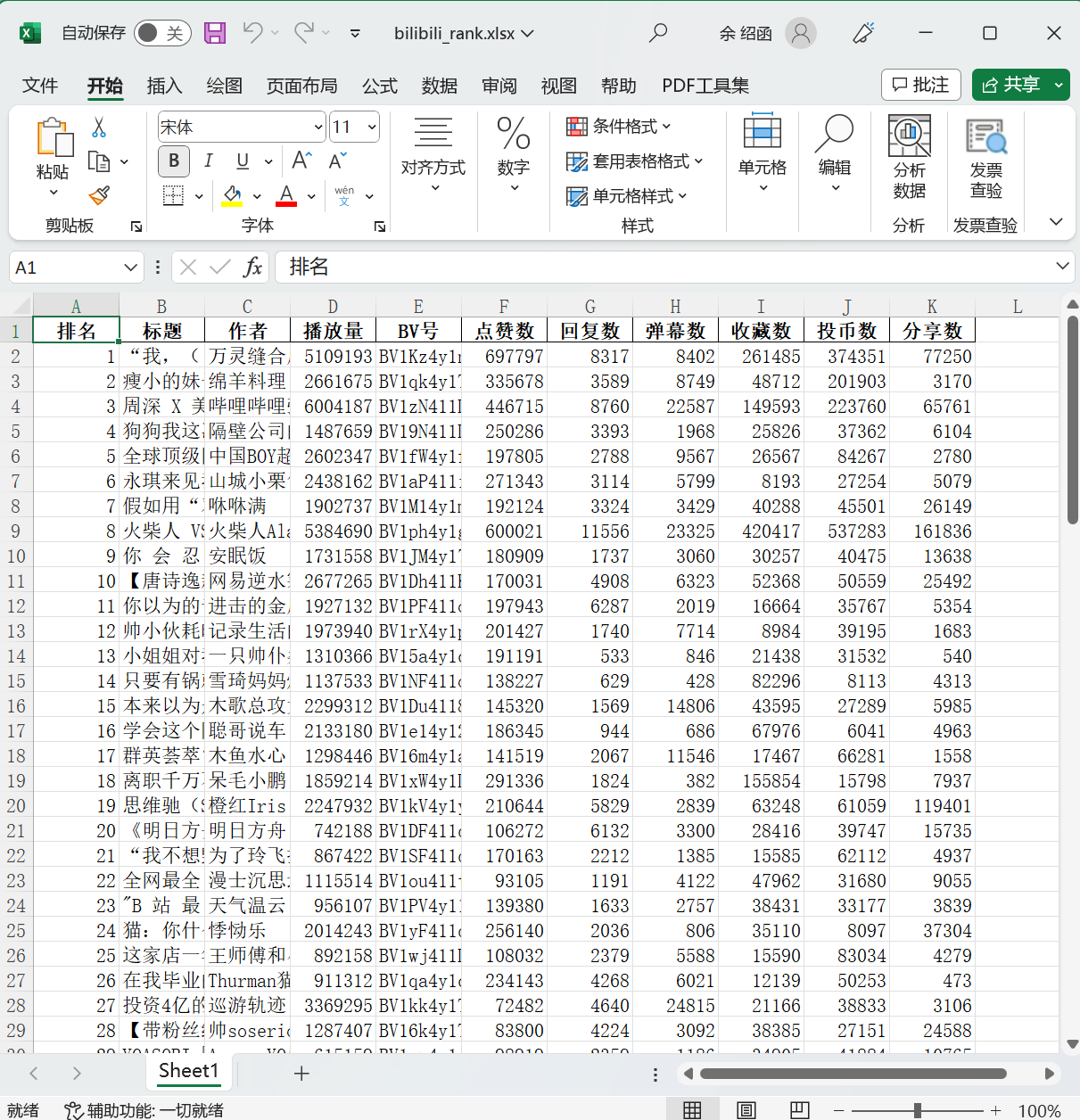
第四部分:拓展部分
- 笔者的代码只做了和播放量相关的数据分析,对于弹幕数、评论数也可以参照此方法进行数据分析。
- 笔者利用播放量等数据预测是/否可以上热门榜显然不太现实,视频的完播率、互动率是更总要的因素。因此,本作业只是用作一次python相关知识的应用,不保证分析的有效性与正确性。